AWS Lambdaのソース管理及びデプロイについて
はじめに
当記事はmeguro.dev#5 で発表したlambdaのソース管理を更に初学者向けに詳細を書いたものです。
AWSアドベントカレンダー 13日目の記事になります。
Infrastructure as Code という言葉があるように、資産のコード管理は非常に重要であることは 既に周知の通りです。 その中で、AWS Lambdaについてはコード管理に関して明確な方法というものはなくチームそれぞれのやり方で行っているのが現状だと思います。
ここでは2つの方法を紹介し、自分のチームでメインに使用しているapexについて更に掘り下げようと思います。
SAM
まず、 AWS Serverless Application Model(AWS SAM) を紹介します。
名前の通りAWS公式のツールであり、CloudFormation拡張のサーバーレスフレームワークです。 CloudFormationと似たDSLでlambda本体及び関連リソースを定義でき、パッケージング/デプロイ共にCLIで統括的に提供されています。
公式だけあり、re:Invent2018で紹介された Lambda Layerにも既に対応しています。
aws cloudformation package --template-file template.yaml --output-template-file serverless-output.yaml --s3-bucket test-reizist aws cloudformation deploy --template-file /Users/reizist/Desktop/lambda/serverless-output.yaml --stack-name sinatra --capabilities CAPABILITY_IAM
のように、まずSAMを定義したtemplateをs3にパッケージングし、その結果を使ってcloudformationでstack作成をする形になります。
APEX
次に、APEXを紹介します。
こちらは非公式ではありますが、lambda自体のソース管理に加えterraform formatなインフラリソースを統合的に管理でき、デプロイ/実行/ログ確認を行えるツールとなっております。
Lambda Layerには現時点で非対応となっておりますが、検討中のようです。
実例
re:Invent2018でLambdaのruby対応が発表されたので、apexを使ってruby及びrubyのweb framework, sinatraをlambdaで動かす実例を紹介します。
pure ruby
まずはシンプルなケースでlambda functionのみのケースとしてrubyを使ってみます。
reizist ...apex test-lambda* $ tree . -L 3 . ├── functions │ └── ruby_job │ ├── function.prod.json │ ├── lambda_function.rb │ └── test.json └── project.prod.json 2 directories, 4 files
ファイル構成はこのようになっています。
lambda_function.rb にlambda functionのソースを記述します。
require 'json' def lambda_handler(event:, context:) { statusCode: 200, body: JSON.generate(event) } end
これをdeployするには以下のようなコマンドを実行します。
reizist ...apex test-lambda* $ apex deploy --env prod ruby_job • config unchanged env=prod function=ruby_job • updating function env=prod function=ruby_job • updated alias current env=prod function=ruby_job version=10 • function updated env=prod function=ruby_job name=reizist_ruby_job version=10
invokeコマンドで実行できます。
reizist ...apex test-lambda* $ apex invoke ruby_job --env prod {"statusCode":200,"body":"{}"}
testパラメータの注入も簡単にできます。
{ "token": "test token" }
reizist ...apex test-lambda* $ apex invoke ruby_job --env prod < functions/ruby_job/test.json {"statusCode":200,"body":"{\"token\":\"test token\"}"}
実行ログを見る場合はlogコマンドを使用します。
reizist ...apex test-lambda* $ apex logs --env prod ruby_job /aws/lambda/reizist_ruby_job START RequestId: d522052a-002f-11e9-9773-430855111917 Version: 11 /aws/lambda/reizist_ruby_job END RequestId: d522052a-002f-11e9-9773-430855111917 /aws/lambda/reizist_ruby_job REPORT RequestId: d522052a-002f-11e9-9773-430855111917 Duration: 47.87 ms Billed Duration: 100 ms Memory Size: 128 MB Max Memory Used: 18 MB
簡単ですね。
sinatra
次にapi gatewayのリソース管理もapexで行うケースをsinatra例に紹介します。 尚アプリケーション実装としては https://github.com/aws-samples/serverless-sinatra-sampleを使っています。
. ├── functions │ └── sinatra_job │ ├── Gemfile │ ├── Gemfile.lock │ ├── app │ ├── function.prod.json │ ├── lambda_function.rb │ ├── test.json │ └── vendor ├── infrastructure │ ├── modules │ │ └── sinatra_job │ └── prod │ ├── main.tf │ └── variables.tf └── project.prod.json 8 directories, 8 files
terraformのmodule機能を使い、インフラのリソースは全てmodule内に閉じ込めて prod/main.tf から参照する構成になっています。またGemfileで管理している依存ライブラリは bundle install --path vendor/bundle としlambda functionのソースと同ディレクトリに含めておく必要がある点に注意です。
こちらも同様に apex deploy した後api gatewayのendpointにwebブラウザでアクセスすると動作が確認できるはずです。
なお今回のソースはgithubに置いておきました。
所感
公式だけあり、SAMは新機能への対応も早く最低限の機能は揃っています。とはいえlambdaのソースをパッケージング->デプロイするのに2段階踏まなくてはいけない点など個人的には少し面倒に感じました。 apexはソース管理の観点ではコマンド1つでデプロイでき、そのまま実行、ログ確認まで行えるので素早さはapexに利があるように感じています。
定義DSLでいうとSAMのDSLを別途理解する必要がある点は不便がありますが、小さい単位ではあとでDSLを見返すと直感的ではあるのかなと感じました。
例えば、今回sinatraを動かすにあたって定義したapi gatewayのリソースはSAMの場合とterraformの場合を比較すると、リソースの依存関係が(インデントのため)SAMのほうが見やすいように思います。
しかしながら規模が大きくなるにつれ、小さい単位に切り出してRef参照を行うなどのことをするとその利点もなくなるので、大規模での管理でいうとterraformが好みです。
チームがもともとインフラのソース管理にterraformを使っているのか、cloudformationを使っているのかでも変わってくるので状況にもよると思いますが、何かの参考になれば幸いです。
弊社におけるSREという考え方の推進
はじめに
締切をしょっぱなから遅れてすみません。 この記事はSREアドベントカレンダー1の2日目 (12/2) の記事となります。
SREという部署/役割がない会社に所属しています @reizist と申します。12/2担当です。 普段はバックエンドを専門的に見ていて、アプリケーション開発をしつつインフラ周りの運用/負債返済をやっているようなロールになります。
弊社においてはインフラを見るメンバーはチームごとに何人かずつ(自分のチームは最近までずっと1人だった)アサインされ、各担当者がそれぞれ思ったように推進形成いくというような構成になっております。 入社から半年ほど経過した時点で、似たような作業をしているにもかかわらずチーム間で知識の横展開等がなく共通知も薄いので各自試行錯誤している部分が少なからずあるように感じるようになりました。
ここから横展開を意識した共通知の形成という観点でSREという概念を扱い、どのような努力を行い、どのように改善しているか、を述べたものが本記事になります。
SREという概念の捉え方
今更ですが、改めて。 SREとは何でしょうか。
ご存知の通りSite Reliability Engineering の略で、日本語ではサイト信頼性エンジニアリングなどと言われていますが、 サイト信頼性と言われて何をするべきか分かる人はまずいないと思います。
SRE本では
サービスの可用性、レイテンシ、パフォーマンス、効率性、変更管理、モニタリング、緊急対応、キャパシティプランニングに責任を負う
と述べられていて(SRE本1.3章 SREの信条)、サービスに関する一切の動作に関して責務を負うことを考えると、
SREのRはResponsibilityだと思ってる
— masahiro nagano (@kazeburo) 2018年11月27日
とあるように Site Responsibility Engineering と認識したほうがなんとなく実態に近いと思います。
ここで最も一番重要な話ですが、SREは何を目的として上記のような非機能要件に責任を負うのでしょうか。
SRE本で
ゴミが散らかったりしないように環境を保つことによってイノベーションにまっすぐ焦点を当て続け本物のエンジニアリングが前進できるようにしているのです
とあるように(9.8章 単純な結論)、あくまで最終的なゴールはサービスの価値向上です。 サービスの価値向上のために運用をエンジニアリングの観点で行うためのベストプラクティスがSRE、と認識しても良いと思います。
自分のケース
現在、自分が所属するチームにおいてはインフラを見る人と機能開発をする人、 というなんとなくの区分けでチーム開発が行われていて、もう少しうまいこと回らないものかと考えあぐねていました。 非機能開発を全てインフラ側にタスクを投げてしまえばインフラ側(少し前まで1人だった)の手が回らなくなってしまう。 とはいえ、インフラを見る人間は、ただインフラを見ているだけでいいかと言われれば、そうではないと思う。 とはいえ手が回らない...結構ありがちな悩みではないでしょうか。
導入事例
前述の通り会社全体としてはSREという概念は存在しておらず、優秀な他社ではどのようなインフラを含めた開発体制(特にSREという文脈で)が敷かれているか非常に興味がありました。 自分がSREという観点でまだまだ経験・認識不足が多いこともあり、 SRE Loungeに参加したところSREの輪読会をやっている話を聞き、これをきっかけに SRE本読書会を始めました。
まずは自分がSREについて自分なりに定義して会社に落とし込み推進できれば、と思い最小コストを意識して初めてみましたが、 嬉しいことに会社内に興味を持ってくれるメンバーが多くいて、現在は8人前後で定期的に開催しており、現在18章まで読み進めることができました。
SRE本読書会の恩恵としては、まずポストモーテムという文化の推進が挙げられると思います。 現時点では2件のみしか事例がありませんが、本来恥ずかしい、隠したい、と考えてしまいがちな失敗事例をポストモーテムとして全体に公開していく、これはまさにGoogleのSREが推進している文化で、失敗による学びを最大化することを目的に行っています。

また、他チームの優秀なエンジニアの方々に知見の共有を頂きながら、SLOの策定やメトリクス/監視系の再設計などを行い始めました。
今後の展望
とはいえ、まだまだ自分に未熟な点が多く大量に課題が残っています。 まだまだ運用安定化のための可視化が足りてないし、開発効率化の観点での負債の返済もできていないし、ユーザーに影響のあるレベルでのパフォーマンス改善は可能な箇所が多く残っています。
日々の運用が快適になるに連れ、チームのメンバーはシステム開発を次のレベルへ進めることを考え始めた
とあるように(SRE本7.4章 自分の仕事の自動化)、運用について悩んでいる間はシステム開発それ自体のレベルが上げるのは難しいと考えているので、サービスのコアバリュー向上という最大の目標に向かってガンガン開発するためにも、 地道に泥臭いところの改善を行っていこうとしています。
まとめ
インフラを扱うにあたり会社内において共通知の形成/知識の横展開が薄かったため、SRE本の勉強会を定期開催することでSREという概念を取り入れ、目線の統一を推進しました。 推進の結果、SLOの策定、ポストモーテムの共有、メトリクス/監視系の再設計など小さいながらも少しずつSRE的な活動が始まっており、今後も更にSREの観点でサービス改善を加速していきたいと考えています。
最後に
SRE本で僕が好きな節と、読書会中に弊社エンジニアが発した名言を一部紹介してこの記事を終えようと思います。
golangの勉強をしている
golang楽しい
golangを勉強している
とはいえ面倒は面倒
やはりruby使いとしてはrubyの手軽さはプログラミング初心者に対して間違いなくプログラミングのハードルを下げているし重要な要素だと思った。
例えば文字列中の変数展開をするとか、Array#map とか、エコシステムが整いまくっててだいだいやりたいことはgemになっていて小回りがきくとかは圧倒的に楽だなぁと改めて思う。
話は変わるが勉強がてら社内で使っている踏み台経由でec2インスタンスのリストを取得しいい感じにsshするcliをgolangに移植しようと試みたが、
rubyでは
exec("ssh user@ip_addr -p port -o 'ProxyCommand ssh bastion_user@bastion_host -p bastion_port -i ~/.ssh/id_rsa -W %h:%p'")
で済んでしまう実装がうまいことgolangで動いておらずに困っている。
いろいろと基本を理解していない恐れもあるのでもう少し基本に立ち返りつつ適当にcliを実装するサイクルを回してみようかなーと思う。
雑魚いなーとか思う人いたらほんとに教えてほしいので PRくださいw
SRE本読書会をやってみる #srelounge
何
SRE Loungeに参加して、改めてSRE本の重要性を感じたのでSRE本読書会を開催します
一人でSRE本読み始める宣言して週に一回業務時間中に読書する時間設けて興味ある人はいつでも参加してくださいみたいな形でやってみようかな #srelounge
— わなびー (@reizist) 2018年9月26日
記念すべき第一回開催は9/28日(金) 19時〜
ポリシー
- 会の開催コストを最小化
- 予習はしない。しちゃだめ。
- 会によるアウトプットを随時行いしおり化
- それぞれの会で前回の振り返り/会のまとめを行いいつでもワードベースでキャッチアップ可能にできたらいいな
フォーマット
- 前回の振り返り(〜10min)
- 新たな章に進むにあたり今までの重要事項を振り返る
- 章を読む(〜15min)
- 1回につき1章が望ましいが開催しつつ読むスピードを考慮して分割を検討する
- 読みつつ気になったワードや事柄をメモ
- 思考/議論(〜20min)
- 上記でメモした内容についてググったり議論を行い知識の定着化を行う
- scrapboxでメモをとるとよさそう
- まとめ(〜15min)
- scrapbox(メモ)の整理と次回の内容の確認/開催日の決定などの必要な準備を行う
備考
- はじめから「誰かやろうぜ!」とかだとぐだるので自分のモチベーションドリブンでまず開催してみる
- とはいえどの回からでも(社内の)誰でも参加可能なようにまとめる努力はしてみる
ECRのイメージ管理がしやすくなっていた
何
ecsでサービスを動かす場合、大抵の場合は自前イメージをecrに置くことになるんじゃないでしょうか。 ecrには 1000 images/ 1repo というイメージ保有制限が存在し、定期的なクリーンが必要ですが、最近のアップデートでかなり対応しやすくなっていたので共有です
どうやるの
ecrにライフサイクルポリシーを設定します。terraform的にはこうです
resource "aws_ecr_lifecycle_policy" "ecr_image_clean_lifecycle_policy" {
count = "${ length(var.ecr-repos) }"
repository = "${ element(var.ecr-repos), count.index) }"
policy = <<EOF
{
"rules": [
{
"rulePriority": 1,
"description": "Expire excess images more than 100",
"selection": {
"tagStatus": "any",
"countType": "imageCountMoreThan",
"countNumber": 100
},
"action": {
"type": "expire"
}
}
]
}
EOF
}
variable "ecr-repos" {
type = "list"
default = ["your-great-repo-name"]
}
補足
ちなみにどうやら先々月にライフサイクルポリシー更新され使いやすくなっていて、 対象のイメージフィルタとして
- タグ
- 個数
- 期間
が存在しましたが、以前はタグ付けされているimageの場合prefixを指定する必要がありました。 つまり git sha1などを使いタグ付けをしていた場合はこれらをフィルタできず、実質タグのないimageのみ削除が可能という微妙な感じだったようです。(ちなみに前にいた会社ではcircle ciでcapistrano task経由によりimage clean scriptを走らせていました)
今回追加された tagStatus: any により、タグ付けされたものも一括で消せるようになり、圧倒的に便利になったのでこれでいけますね。
redashを0.12 -> 4.0.1のアップグレードした作業ログ
何
(あまりまともに運用されていない)redashがもともとredash-v0.12.0.b2449 で動いていたが Redash1.0.3で日本語を含むTreasureDataのクエリがエラーになるらしい という報告をもらい対応を検討した結果、容易にアップグレードできそうだったので対応してみたところハマった
背景
http://blog.web.nifty.com/engineer/701
のように、古いredashではtd-clientのversionが古く日本語を含むクエリが動かないのでアップグレードしてほしい、という軽い相談を受けた。
前述のブログによれば td-client が0.8.0以降で改修されているという記述があったので試してみたところ、 Error running query: job error: 328215861: error という謎のエラーが発生し解決しなかった。
pip install td-client==0.8.0 pip list | grep td-client supervisorctl restart all
redashのupgradeについて調査をしてみたところ、 https://redash.io/help/open-source/admin-guide/how-to-upgrade にキレイにアップグレードの方法がまとまっていたので、数年前のredashを積極的に使う理由もないし簡単にできそうだったのでアップグレードをすることにした。 なおコンテナで動かす方向も検討したが、redashはそれまでほぼ誰も使っておらず今後の使用頻度にもあまり期待はできなさそうだったのでアップグレードを採用した。
何にハマったか
今回は0.12 -> latestのupgradeだったので前述のリンクの
How to upgrade (pre v1.0.0 versions)
に該当し、記述通りの対応を行った。
cd /opt/redash sudo cp -r redash-v0.12.0.b2449 redash-v0.12.0.b2449-backup cd /opt/redash/current wget https://raw.githubusercontent.com/getredash/redash/master/bin/upgrade chmod +x upgrade vim .env # REDASH_STATIC_ASSETS_PATHを消す sudo ./upgrade
実行したところ、
Downloading release tarball... Unpacking to: redash.4.0.1.b4038... Changing ownership to redash... Linking .env file... Installing new Python packages (if needed)... Running migrations (if needed)...
とログが流れ、最後のmigrationが時間がかかっているようだったのでバックグランド実行に切り替え退社(20:30)し、優雅にジムに行き2km泳ぎ、気分良く帰宅し「よーしmigration終わったやろ」と言って psql して SELECT * FROM pg_stat_activity; した(1:30)ところ、 idle in transaction で数時間止まっているクエリを発見した。
migrationが終わっていない....
ひとまずmigrationが問題であることがわかったのでmigrationを単体で実行してみる。
[ec2-user@ip-xxx-xxx-xxx-xxx redash.4.0.1.b4038]$ pwd /opt/redash/redash.4.0.1.b4038 bin/run ./manage.py db upgrade
しかし、 Update widget’s position data based on dashboard layout.
Updating dashboards position data: でstuckして十数分待ってもmigrationが終わらない。
どうしたものかと思いぐぐったところ、全く同じ現象でハマッた人がおり、 0.12 -> 4.0.1の前に 3.0を経由したら動いた とのことだった。 んなアホな
物は試しと3.0へのupgradeを試みる。 アップグレード対象のversionはどうやらAPIから取得しているようだった。
def get_release(channel): if channel == 'ci': return get_latest_release_from_ci() response = requests.get('https://version.redash.io/api/releases?channel={}'.format(channel)) release = response.json()[0] filename = release['download_url'].split('/')[-1] release = Release(release['version'], release['download_url'], filename, release['description']) return release
APIのレスポンスを見ると、
[{"id":28,"version":"4.0.1","channel":"stable","download_url":"https://s3.amazonaws.com/redash-releases/redash.4.0.1.b4038.tar.gz","backward_compatible":false,"released_at":"2018-05-02T00:00:00.000Z","description":"* Before doing an upgrade, please make sure you have a backup.\n* If you have any issues, please refer to the troubleshooting section in the upgrade guide:\n https://redash.io/help/open-source/admin-guide/how-to-upgrade\n* If the upgrade guide doesn't help, you can ask for help on the forum (https://discuss.redash.io). \n\nFull CHANGELOG for this release: https://github.com/getredash/redash/blob/master/CHANGELOG.md","docker_image":"redash/redash:4.0.1.b4038"},{"id":27,"version":"4.0.0","channel":"stable","download_url":"https://s3.amazonaws.com/redash-releases/redash.4.0.0.b3948.tar.gz","backward_compatible":false,"released_at":"2018-04-16T00:00:00.000Z","description":"* Before doing an upgrade, please make sure you have a backup.\n* If you have any issues, please refer to the troubleshooting section in the upgrade guide:\n https://redash.io/help/open-source/admin-guide/how-to-upgrade\n* If the upgrade guide doesn't help, you can ask for help on the forum (https://discuss.redash.io). \n\nFull CHANGELOG for this release: https://github.com/getredash/redash/blob/master/CHANGELOG.md","docker_image":"redash/redash:4.0.0.b3948"},{"id":23,"version":"3.0.0","channel":"stable","download_url":"https://s3.amazonaws.com/redash-releases/redash.3.0.0.b3134.tar.gz","backward_compatible":true,"released_at":"2017-11-13T00:00:00.000Z","description":"* Before doing an upgrade, please make sure you have a backup.\n* If you have any issues, please refer to the troubleshooting section in the upgrade guide:\n https://redash.io/help-onpremise/maintenance/how-to-upgrade-redash.html\n* If the upgrade guide doesn't help, you can ask for help on the forum (https://discuss.redash.io). \n\nFull CHANGELOG for this release: https://github.com/getredash/redash/blob/master/CHANGELOG.md","docker_image":"redash/redash:3.0.0.b3134"},{"id":22,"version":"2.0.1","channel":"stable","download_url":"https://s3.amazonaws.com/redash-releases/redash.2.0.1.b3080.tar.gz","backward_compatible":true,"released_at":"2017-10-22T00:00:00.000Z","description":"* Before doing an upgrade, please make sure you have a backup.\n* If you have any issues, please refer to the troubleshooting section in the upgrade guide:\n https://redash.io/help-onpremise/maintenance/how-to-upgrade-redash.html\n* If the upgrade guide doesn't help, you can ask for help on the forum (https://discuss.redash.io). \n\nFull CHANGELOG for this release:\nhttps://github.com/getredash/redash/blob/master/CHANGELOG.md#v201---2017-10-22","docker_image":null},{"id":21,"version":"2.0.0","channel":"stable","download_url":"https://s3.amazonaws.com/redash-releases/redash.2.0.0.b2990.tar.gz","backward_compatible":true,"released_at":"2017-08-08T00:00:00.000Z","description":"* Before doing an upgrade, please make sure you have a backup.\n* If you have any issues, please refer to the troubleshooting section in the upgrade guide:\n https://redash.io/help-onpremise/maintenance/how-to-upgrade-redash.html\n* If the upgrade guide doesn't help, you can ask for help on the forum (https://discuss.redash.io). \n\nFull CHANGELOG for this release: https://github.com/getredash/redash/blob/master/CHANGELOG.md#v200---2017-08-08","docker_image":null}]
のようになっておりchannel: stableの3つめのレスポンスを使えばよさそうということがわかったので、
- release = response.json()[0] + release = response.json()[2]
とし
sudo ./upgrade --channel stable
を実行したところ、速攻3.0へのupgradeが終わってしまった。なんでやねん...と思いつつもう一度upgradeを実行したところ素直に4.0.1にあがった。 なんでやねん
所感
- ゴリ押し感半端ない
- 素直にcontainerで動かせばこんな苦労はないので、僕のような悪い大人にはならないようにしましょう
補足
redash4.0にあげたことによりクエリ失敗時のエラーログに詳細の理由が出るようになった結果、 今回のクエリは
Error running query: job error: 328361382: error: Query 20180814_173306_79597_yerrm failed: line 15:12: Table td-presto.xxx.xxx_orders does not exist
というように失敗していたので別の理由もあったことがわかり結果的にはredashあげてよかったですね。
prestodbにおけるelapsed timeとは何か
prestodbを扱っていてクエリメトリクスを見る上で必ず参照することになるelapsed timeが一体何なのかを調べたメモ。 一言でいうとクエリが作成されてからクエリが完了するまでの時間なんだけど、じゃあそれがいつなのかというのをソースを追う。
全体の流れを追うのに、
https://www.slideshare.net/frsyuki/hadoop-source-code-reading-15-in-japan-presto
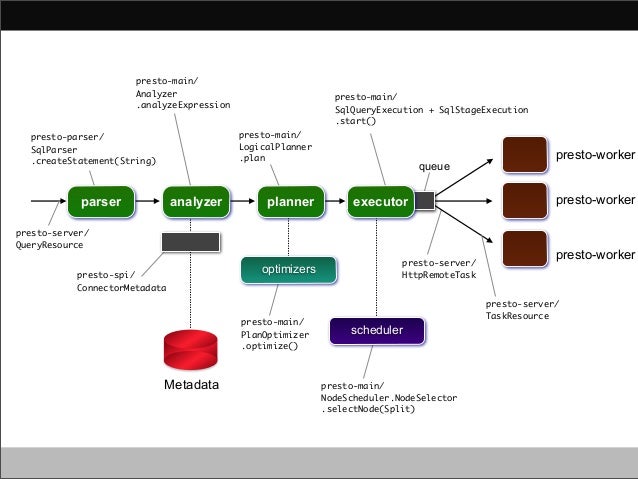
presto_executor_and_coordinator.md · GitHub
あたりが非常に参考になるので足がかりにするとよい。
実際に createTime , endTime を作成しているのは QueryStateMachine 内で、
createTime:QueryStateMachineインスタンス作成時
endTime:recordDoneStats()コール時transitionToFinished()ortransitionToFailed()ortransitionToCanceled()の処理内でrecordDoneStats()が呼ばれる
実際に QueryStateMachine のインスタンスは SqlQueryExecution のコンストラクタ内で作成され、 transitionToXXX() は com.google.common.util.concurrent.Futures#addCallback() によって onSuccess() などのcallbackとして処理される。
SqlQueryExecution のオブジェクトは SqlQueryManager#createQuery によって作成される。
メトリクスを把握するのによく参照する時間周りのまとめ。
| タイプ | 値 | 処理クラス |
|---|---|---|
| createTime | クエリ作成時間 | QueryStateMachine |
| startTime | 実際のクエリ処理開始時間 | Session |
| endTime | 実際のクエリ処理完了時間 | QueryStateMachine |
| queuedTime | duration(startTime - createTime) | QueryStateMachine |
| elapsedTime | duration(endTime - createTime) | QueryStateMachine |
| executionTime | elapsedTime - queuedTime | QueryStats |
雑いけどひとまずメモ。